奇异值分解
方阵情况:
\(Ax=λx\) A是一个n×n的实对称矩阵,x是一个nn维向量,则我们说λ是矩阵A的一个特征值,而x是矩阵A的特征值λ所对应的特征向量.可以将矩阵A特征分解 \(A=W\Sigma W^{-1}\) 其中W是这n个特征向量所张成的n×n维矩阵,而Σ为这n个特征值为主对角线的n×n维矩阵,把特征向量标准化,则这n个特征向量为标准正交基,满足$W^TW=I$ 这样我们的特征分解表达式可以写成 \(A=W\Sigma W^T\)
非方阵情况
任何实矩阵A∈Rm×n都可以分解为
\(\mathbf{A}=\mathbf{U}\Sigma\mathbf{V}^T\)
其中U和V都是酉矩阵,满足
\(\mathbf{U}^T\mathbf{U}=\mathbf{I}\text,\mathbf{V}^T\mathbf{V}=\mathbf{I},(\Sigma)_{ii}=\sigma_i\),且其它位置的元素均为0,\(\sigma_i>0\)
为奇异值,
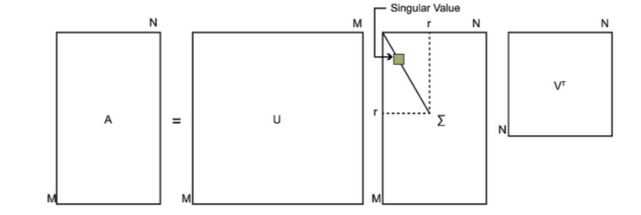
如何求SVD分解后的U,Σ,V这三个矩阵? m×m方阵\(AA^T\)的所有特征向量张成U矩阵,n×n方阵$A^TA$的所有特征向量张成V矩阵 证明: \(A=U\Sigma V^T\Rightarrow A^T=V\Sigma^TU^T\Rightarrow A^TA=V\Sigma^TU^TU\Sigma V^T=V\Sigma^2V^T\) 特征值和奇异值满足如下关系 \(\sigma_i=\sqrt{\lambda_i}\)
范数
p范数
对于\(x=(x_1,x_2,\cdots,x_m)\),p范数定义为 \(\|x\|_p=\sqrt[p] { \sum_{ i=1 }^mx_i^p }\) 而p-范数中,最常见的就是p=2的情形,它就是我们经常说的向量模长,也叫“欧几里得范数”,如果省略范数的下标只写‖x‖,那么基本上就是默认p=2。
矩阵的F范数
直接将矩阵展平为向量来计算: \(\|M\|_F=\|\operatorname{vec}(M)\|_2=\sqrt{\sum_{i=1}^n\sum_{j=1}^mM_{i,j}^2}\)
矩阵的谱范数(2-范数)定义
\(\|A\|_2=\max_{\|x\|_2=1}\|Ax\|_2\) 矩阵的谱范数是其最大的奇异值
伪逆
是“逆矩阵”的概念对于不可逆矩阵的推广。 对于AB=M,如果想求得\(B=A^{-1}M\),需要A可逆,如果A不可逆或A不为方阵,需要转化为优化问题: \(\underset{B}{\operatorname*{argmin}}\|AB-M\|_F^2\) F范数(Frobenius Norm),用来衡量矩阵AB−M与全零矩阵的距离,定义为 \(\|M\|_F=\sqrt{\sum_{i=1}^n\sum_{j=1}^mM_{i,j}^2}\) 从求精确的逆矩阵改为最小化AB与M的平方误差
低秩逼近
问题就是我们希望用一个秩不超过r的矩阵D^去逼近原始矩阵D,使得他们俩之间的F范数最小 矩阵的奇异值分解为 \(D=U \Sigma V^{\top} \in \mathbb{R}^{m \times n}, \quad m \leq n \\\) 根据已知的秩的约束,我们可以将对应的矩阵分为两部分 \(U=:\left[\begin{array}{ll} U_1 & U_2 \end{array}\right], \Sigma=:\left[\begin{array}{cc} \Sigma_1 & 0 \\ 0 & \Sigma_2 \end{array}\right], V=:\left[\begin{array}{ll} V_1 & V_2 \end{array}\right]\\\) 其中\(U_1\in\mathbb{R}^{m\times r},\Sigma_1\in\mathbb{R}^{r\times r},V_1\in\mathbb{R}^{r\times n}\) 即由前面的分块矩阵相乘得到的秩为r的部分为 \(\widehat{D}^*=U_1 \Sigma_1 V_1^{\top} \\\) 则$\widehat{D}^{*}$就是上述问题的最优解 \(\left\|D-\widehat{D}^*\right\|_{\mathrm{F}}=\min _{\operatorname{rank}(\widehat{D}) \leq r}\|D-\widehat{D}\|_{\mathrm{F}}=\sqrt{\sigma_1^2+\cdots+\sigma_r^2} \\\)
证明:从2范式角度
在分好块的基础上: \(D=U\Sigma V^T=\left[\begin{array}{ll} U_1 & U_2 \end{array}\right]\left[\begin{array}{cc} \Sigma_1 & 0 \\ 0 & \Sigma_2 \end{array}\right]\left[\begin{array}{cc} V_1^T \\ V_2^T \end{array}\right]\\\) \(=\left[\begin{array}{ll} U_1\Sigma_1 & U_2\Sigma_2 \end{array}\right]\left[\begin{array}{cc} V_1^T \\ V_2^T \end{array}\right] \\\) \(=U_1\Sigma_1 V_1^T+U_2\Sigma_2 V_2^T \\\) \(=\sum_{i=1}^{\color{red}r} \sigma_i u_i v_i^{\top}+\sum_{i={\color{red}r+1}}^n \sigma_i u_i v_i^{\top} \\\) 假设第一部分为\(D_r\),则需要证明对任意秩小于等于r的m×n矩阵$B_r$,都有 \(\|D-D_r\|_2\leq \|D-B_r\|_2 \\\) 而 \(\|D-D_r\|_2=\|\sum_{i={\color{red}r+1}}^n \sigma_i u_i v_i^{\top}\|_2=\sigma_{r+1} \\\)(最大的奇异值) 所以只需要证明右边大于等于原矩阵D的第r+1个奇异值即可
满秩分解 对于m×n的矩阵A,若其秩为k,若存在秩同样为k的两个矩阵\(F_{m\times k}\)(列满秩)和\(G_{n\times k}\)(列满秩),使得\(A=FG^T\),则称其为矩阵A的满秩分解。
- 任何非零矩阵一定存在满秩分解
- 满秩分解不唯一
我们先对任意秩小于等于r的矩阵Br做一个关于维数r的分解$B_r=XY^T$其中\(X\in\mathbb{R}^{m\times r},Y^T\in\mathbb{R}^{r\times n}\) 如果Br的秩刚好为r,直接用它的满秩分解即可,若秩小于r,则在它对应的满秩分解后补0凑够r列即可。
对于\(Y^T w=0\)这个线性方程组,由于这里至多只有r个线性无关的向量,很容易在正交矩阵V∈Rn×n中找到r+1个线性无关的向量使得
\(w=\gamma_1 v_1+\cdots+\gamma_{r+1}v_{r+1} \\\)使得\(Y^Tw=0\)
并且我们可以对w的系数做一个规范化,使得
\(\|w\|_2=\gamma_1^2+\cdots+\gamma_{r+1}^2=1 \\\)
由Cauchy-Schwarz不等式的向量形式
\(|\mathbf{a}\cdot\mathbf{b}|\leq\|\mathbf{a}\|\|\mathbf{b}\|\)
\(1\cdot \|D-B_r\|^2_2=\|w\|_2^2\|D-B_r\|^2_2\geq \|(D-B_r)w\|^2_2 \\\)
而
\(B_rw=X(Y^Tw)=X\mathbf{0}=\mathbf{0} \\\)
所以右边只剩下
\(\|Dw-\mathbf{0}\|^2_2 \\\)
\(V_{n\times n}=\left[\begin{array}{ll} v_1,\cdots,v_{r+1}\bigg|\cdots,v_{n} \end{array}\right]\\\)
\(V_{n\times n}^T=\left[\begin{array}{ll} v_1^T\\ \vdots\\v_{r+1}^T\\ \hline \vdots\\ v_{n}^T \end{array}\right]\\\)
\(\boldsymbol{\gamma}=\left[\begin{array}{ll} \gamma_1,\cdots,\gamma_{r+1} \end{array}\right]^T\in\mathbb{R}^{(r+1)\times 1}\)
那么由前面所找到的向量组,
\(w_{n\times 1}=V_{n\times (r+1)}^{\#}\boldsymbol{\gamma}_{(r+1)\times 1}=\left[\begin{array}{ll} v_1,\cdots,v_{r+1} \end{array}\right]\left[\begin{array}{ll} \gamma_1\\\vdots\\\gamma_{r+1} \end{array}\right]\\\)
\(Dw=U\Sigma V^T V^{\#}\boldsymbol{\gamma} \\\)
根据结合律,先计算
\(V^T V^{\#}\)
,由于V为正交矩阵,结果可以写成如下的分块矩阵:
\(V^T_{n\times n} V^{\#}_{n\times (r+1)}=\left[\begin{array}{ll} v_1^T\\ \vdots\\v_{r+1}^T\\ \hline \vdots\\ v_{n}^T \end{array}\right]\left[\begin{array}{ll} v_1,\cdots,v_{r+1} \end{array}\right]=\left[\begin{array}{ll} \boldsymbol{I}_{r+1}\\ \boldsymbol{0}_{(n-r-1)\times (r+1)} \end{array}\right]_{n\times (r+1)}\\\)
\(\left[\begin{array}{ll} \boldsymbol{I}_{r+1}\\ \boldsymbol{0}_{(n-r-1)\times (r+1)} \end{array}\right]_{n\times (r+1)}\left[\begin{array}{ll} \gamma_1\\\vdots\\\gamma_{r+1} \end{array}\right]_{(r+1)\times 1}=\left[\begin{array}{lll} \gamma_1 \\ \vdots\\ \gamma_{r+1} \\ \boldsymbol{0} \end{array}\right]_{n \times 1}\)
再计算前面的
\(\Sigma_{m\times n}\left[\begin{array}{lll} \gamma_1 \\ \vdots\\ \gamma_{r+1} \\ \boldsymbol{0} \end{array}\right]_{n \times 1}=\left[\begin{array}{lll} \sigma_1 \\ &\ddots\\ &&\sigma_{r+1}& &&\boldsymbol{0}\\ &&&\ddots\\ &&&&\sigma_{rank(D)} \\ \qquad\boldsymbol{0} \end{array}\right]_{m \times n}\left[\begin{array}{lll} \gamma_1 \\ \vdots\\ \gamma_{r+1} \\ \boldsymbol{0} \end{array}\right]_{n \times 1}=\left[\begin{array}{lll} \sigma_1\gamma_1 \\ \vdots\\ \sigma_{r+1}\gamma_{r+1} \\ \boldsymbol{0} \end{array}\right]_{m \times 1}\\\)
可以得到
\(Dw=U_{m \times m}\left[\begin{array}{lll} \sigma_1\gamma_1 \\ \vdots\\ \sigma_{r+1}\gamma_{r+1} \\ \boldsymbol{0} \end{array}\right]_{m \times 1}\\\)
U是酉矩阵,列向量互相垂直且模长为1
\(Dw=\left[\begin{array}{lll} u_1 \cdots u_m \end{array}\right]_{m \times m}\left[\begin{array}{lll} \sigma_1\gamma_1 \\ \vdots\\ \sigma_{r+1}\gamma_{r+1} \\ \boldsymbol{0} \end{array}\right]_{m \times 1}=\sigma_1\gamma_1 \boldsymbol{u_1}+\cdots+\sigma_{r+1}\gamma_{r+1} \boldsymbol{u_{r+1}}\\\)
这里求得是向量的2范数,所以直接为所有元素的平方和
\(\|Dw\|_2^2=\sigma_1^2\gamma_1^2 +\cdots+\sigma_{r+1}^2\gamma_{r+1}^2 \\\)
由于\(\gamma_1^2 +\cdots+\gamma_{r+1}^2=1\)且 \(\sigma_1\geq\sigma_2\geq\cdots\geq\sigma_{r+1}\)
所以\(\sigma_1^2\gamma_1^2 +\cdots+\sigma_{r+1}^2\gamma_{r+1}^2\geq \sigma_{r+1}^2 \\\)
\(\|D-D_r\|_2^2={\color{blue}\sigma_{r+1}^2\leq \sigma_1^2\gamma_1^2 +\cdots+\sigma_{r+1}^2\gamma_{r+1}^2}=\|D-B_r\|_2^2 \\\)
证毕
证明:从F范式角度
思路一样,先计算 \(\|D-D_{r}\|_F^2=\|\sum_{i={\color{red}r+1}}^n \sigma_i u_i v_i^{\top}\|_F^2 \\\) 因为后半部分矩阵的奇异值就是\(\sigma_{r+1}\cdots\sigma_{n}\),F范数平方的等价定义是奇异值的平方的和,所以上式就直接等于\(\sum_{i=r+1}^n \sigma_{i}^2\) 只需要证明对任意秩不超过r的矩阵Br \(\|D-B_{r}\|_F^2\geq \sum_{i=r+1}^n \sigma_{i}^2=\|D-D_{r}\|_F^2 \\\) 左边的展开式为 \(\|D-B_{r}\|_F^2=\sum_{i=1}^{n}\sigma_i^2(D-B_{r})\\\) (等于矩阵所有奇异值的平方和)
借助Weyl定理的奇异值版本,对任意的m×n的矩阵A,B,有下式成立 \(\sigma_{i+j-1}(A+B)\leq \sigma_i(A)+\sigma_j(A) \\\) 借用这个结论,我们可以令\(A=D-B_r,B=B_r\) \(\sigma_{\color{blue}i+j-1}(D)\leq \sigma_{\color{blue}i}(D-B_r)+\sigma_{\color{blue}j}(B_r) \\\) 取\(i=1,j=r+1\) \(\sigma_{r+1}(D)\leq \sigma_1(D-B_r)+\sigma_{r+1}(B_r) \\\) 由于Br的秩不超过r,所以 \(\sigma_{r+1}(B_r)=0\),所以有\(\sigma_{r+1}(D)\leq \sigma_1(D-B_r) \) 同样地再取\(i=2,\cdots,(n-r-2);j=r+1\),把各项平方再相加,我们就证明了 \(\|D-B_{r}\|_F^2={\color{blue}\sum_{i=1}^{n}\sigma_i^2(D-B_{r})\geq \sum_{i=r+1}^n \sigma_{i}^2}=\|D-D_{r}\|_F^2 \\\)
相当于D先做了一个奇异值分解,然后取前r个奇异值,取完之后用奇异值分解的公式还原回D,D就可以作为近似矩阵 SVD分解后的秩r截断是原优化问题的最优解,可以用来做低秩逼近。
参考:
- https://en.wikipedia.org/wiki/Low-rank_approximation
- https://xixuhu.github.io/_posts/2023-02-15-svd
- https://zh.wikipedia.org/wiki/%E7%9F%A9%E9%99%A3%E7%AF%84%E6%95%B8
- https://spaces.ac.cn/archives/10366